AMD предлагает Dynamic Local Mode для Ryzen Threadripper; прирост в играх до 47%
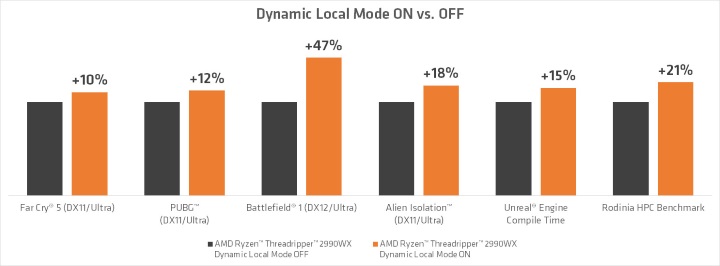
AMD сделала в своём блоге весьма интересный пост о предстоящей функции под названием «Dynamic Local Mode» для своих флагманских процессоров Ryzen Threadripper, которая поможет улучшить производительность в играх, причём до 47% в отдельных случаях. Но теперь обо всём по порядку.
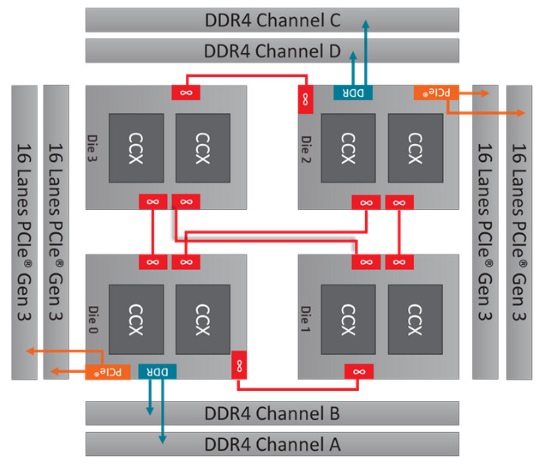
Известно, что мульти-чиповый пакет Threadripper имеет 4 матрицы, из которых только две получают прямой доступ к модулям памяти. Остальные две плашки для обращения к памяти должны уповать на Infinity Fabric, что характеризуется приличными задержками. Этот принцип не влияет на ресурсоёмкие приложения, использующих для работы кэш CPU или незначительное обращение к памяти. А вот другие приложения, особенно игры, распределяют свою рабочую нагрузку по нескольким ядрам, некоторые из которых в конечном итоге имеют более высокую задержку памяти, чем ожидалось, что и приводит к неоптимальной производительности.
Концепция нескольких процессоров с разными путями доступа к памяти называется NUMA (Non-uniform memory access). В то время как на уровне программного обеспечения есть возможность технически обнаружить конфигурацию NUMA и присоединить каждый поток к идеальному ядру процессора, однако большинство приложений не поддерживают NUMA, а также скорость принятия очень медленная, и всё это вероятно, из-за малого количества систем, использующих такую концепцию.


В Threadripper, применяется Ryzen Master, посредством, которого пользователи могут свободно переключаться между режимами «Local Memory Access» или «Distributed Memory Access», при этом последний вариант является значением по умолчанию для Threadripper, в результате, режим максимизирует производительность приложения. Первый вариант, с другой стороны, лучше подходит для игр, но переключение между режимами требует перезагрузки, что неудобно для пользователя.
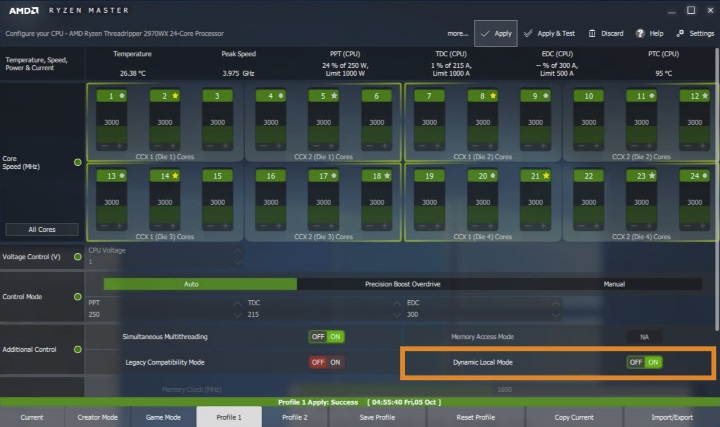
Новый «Dynamic Local Mode» AMD направлен на отмену этого наследия путем внедрения фонового процесса, который постоянно контролирует все запущенные приложения и использование CPU для них, а главное, подталкивает более ресурсоёмкие на ядра, имеющие прямой доступ к памяти, путем настройки маски слияния процессов, выбирающей, на какие процессы разрешено запланировать приложение. Приложения, для которых требуется очень мало CPU, в свою очередь, направляются на ядра без прямого доступа к памяти, потому что они не столь важны для скорого исполнения.






")