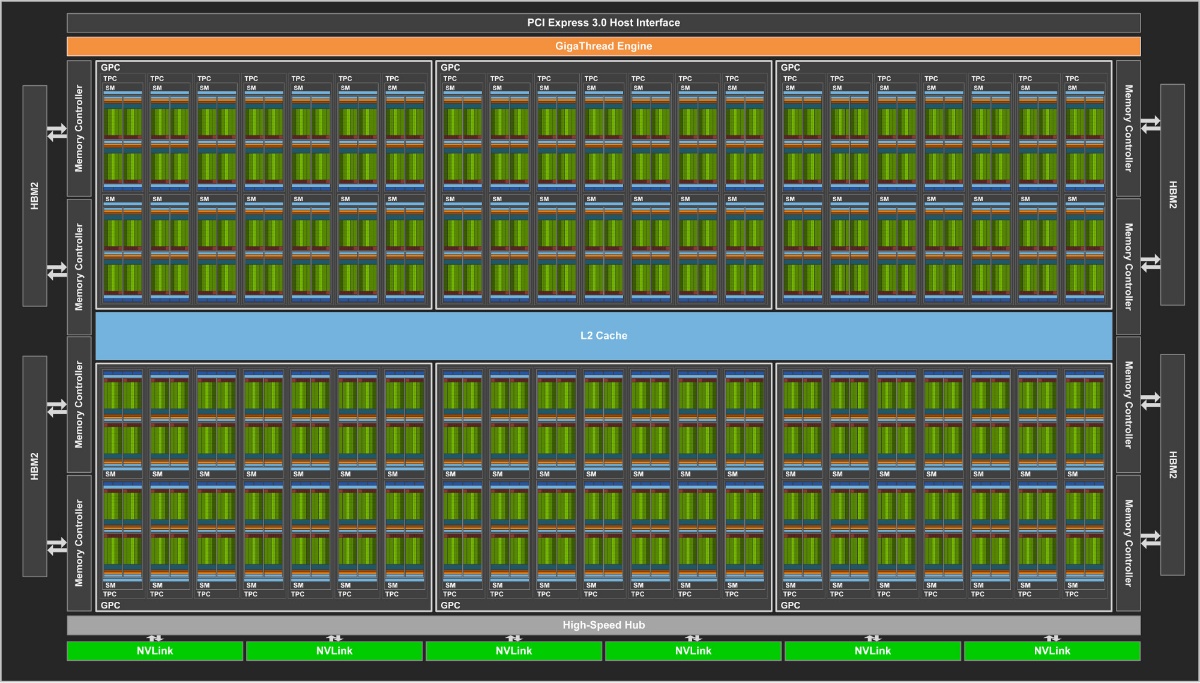
NVIDIA на мероприятии GTC 2017, анонсировала архитектуру нового поколения «Volta». Как и в случае с нынешней архитектурой «Pascal», «Вольта» была представлена в своей самой большой и функциональной реализации — плате Tesla V100 HPC, управляемой GPU GV100. Учитывая применение HPC в продуктах семейства продуктов Tesla от NVIDIA, у GV100 есть определённые компоненты, которые не попадут в потребительскую семью GeForce. Несмотря на это, GV100 является вершиной инженерной разработки NVIDIA. Согласно блок-схеме графического процессора, выпущенной компанией, GV100 имеет похожую иерархию компонентов с чипами предыдущего поколения от NVIDIA, но с некоторыми существенными изменениями в базовой вычислительной машине, потоковом мультипроцессоре (SM — streaming multiprocessor).
SM Volta на кристалле GV100 имеет ядра CUDA как для FP32, так и FP64. Потребительские графические реализации Volta, будущие продукты GeForce, могут не получить специализированных ядер FP64. Далее. Каждый SM имеет 64 ядра FP32 и 32 ядра FP64. Ядра FP64 могут обрабатывать 32, 16 и даже примитивные 8-битные операции. Чип GV100 имеет 80 SM: 5.120 FP32 и 2.560 FP64 ядер CUDA. Кроме того, Volta вводит компонент под названием «Tensor core», специализированный механизм, предназначенный для ускорения обучения и построения нейронной сети. Каждый SM несёт 8 из них, поэтому GV100 в сумме получает 640. Как и в случае с ядрами FP64, тензорные ядра могут не соответствовать реалиям потребительской графики. Учитывая количество SM, GV100 имеет 320 TMU. NVIDIA разогнала GV100 до 1455 МГц.
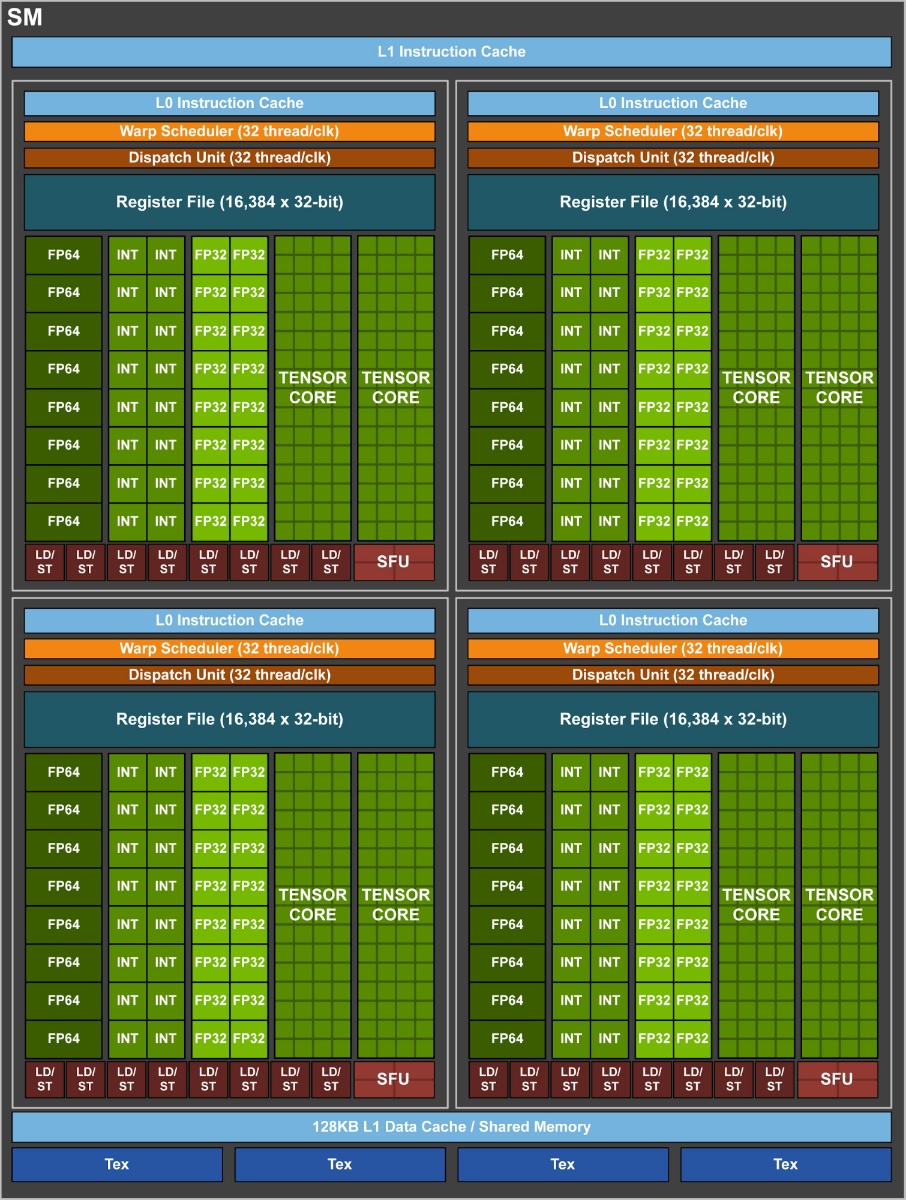
Объявлено, что Tesla V100 обеспечивает максимальную производительность FP32 и FP64 на 50% по сравнению с Pascal. Его максимальная пропускная способность FP32 оценивается в 15 TFLOP/s, с максимальной пропускной способностью 7.5 TFLOP/s для FP64. Тензорные ядра «эффективно» работают на скорости 120 TFLOP/s, чтобы выполнять свою очень специализированную задачу обучения глубоких нейронных сетей. Эти компоненты имеют матричные единицы умножения, ключевой математической операцией в обучении нейронной сети. Они ускоряют постройку/тренировку нейронной сети в 12 раз.

Построенный на новом 12-нанометровом процессе, GV100 является многочиповым модулем с площадью кристалла 815 мм² с гигантским количеством транзисторов 21.1 миллиарда, рядом соседствуют четыре 32-гигабитных микросхемы памяти HBM2, объём которой составляет 16 ГБ. Эти стеки взаимодействуют с GV100 посредством 4096-битного интерфейса памяти через кремниевый интерполятор. С эффективной частотой 1 ГГц, GV100 обеспечивается пропускной способностью в районе 1 ТБ/с. Память HBM2 все ещё остаётся эксклюзивной для семейства Tesla в продуктовой линейке NVIDIA, поскольку она продолжает быть дорогостоящей в потребительском сегменте для NVIDIA. Однако потребительские реализации «Вольта» могут включать недорогую, но довольно быструю память GDDR6. Одни из новаторских производителей HBM, SK Hynix, даже продемонстрировал GDDR6 в GTC, поэтому, если NVIDIA не собирается бороться за очередной отрыв-скачок в производительности по сравнению с продуктами AMD, ожидаемо, что компания станет придерживаться GDDR6 в потребительском сегменте.

Карточка Tesla V100 HPC будет разработана в двух пакетах: интегрированных плат с интерфейсом NVLink для более высокой плотности сборки ферм и дополнительных плат с интерфейсом PCI-Express для рабочих станций. Продажа будет осуществляться по специализированным розничным каналам.
С уважением, procompsoft.ru





